Intro to Artificial Intelligence
Artificial Intelligence, or AI, is a huge field which includes all the theories like mathematical formulas but also phylosophical and ethical views related to the creation of intelligence different from the biological one, this field also covers the methodologies and all the algorithms which are practically used to create "smart machines".
The main objective of AI is to solve problems that require some sort of "intelligence". Intelligence does not have a specific definition but it has many aspects such as logic, critical-thinking, problem-solving but also creativity and they are all different from each other. Broadly speaking, from a qualitative point of view, the main goal is to mimic human mind which is essentially a simulation of a brain inside a computer. Artificial Intelligence can be divided in Weak AI and Strong AI:
- Weak AI is what we currently have, essentially an AI which is able to perfom specific tasks such as playing a board game (Figure 1) or translating some text or recognizing a face. These are all examples of AIs which focus on a specific domain and typically cannot do anything else outside their main domain.
- On the other hand, Strong AI is an hypotethical stage where the machine can essentially reach Artificial General Intelligence (AGI). This essentially means that the machine can think like a human. If this stage is reached then there are speculations that the AI can reach what is called a "Singularity" where the machine complexity will grow exponentially and beyond human comprension.


This field has several subfields which have specific objectives, the most well-known are:
- Planning: this field is related to the development of strategies or actions which are executed by intelligent agents. An agent (like an autonomous robot or an unmanned vehicle) makes a representation of the state of the world which is useful to plan and make predictions on how actions performed by it will affect the world and then attempts to make choices to maximize the probability of achieving a certain objective. The agents can be alone or can collaborate with other agents in order to create new emergent behaviors which further increase their chances of success.
- Expert Systems: these are systems especially used in the early days of AI and they are programmed to emulate the decision-making ability of a human expert. They are created to solve some specific complex problems and typically they use "if-then" rules to navigate through the different possible scenarios and propose the optimal solution. These system mainly rely on the knowledge of the designer of these system which should take into account enough scenarios of the complex problem and, if done well, they can give the user the sense that the systems are actually intelligently able to solve the proposed complex problem or guide the user to specific solutions.
- Natural Language Processing: this field attempts to create methodologies able to deal with the human language like for example read a text and being able to highlight the main content or extract information or categorize the content. These methodologies are able to process and analyze large amounts of natural language data and lately the goal is to effectively make them understand the actual content and context provided. The field takes into account written and oral language, so some of the uses are in understanding or generating text but focuses also in areas like speech recognition.
- Computer Vision: this field is related to the goal of extrapolating meaningful information from cameras/videos/images. The methodologies need to be able to acquire and process the information in order to be able to extract relevant data: the images need to be transformed into abstract concepts or descriptions that humans are able to understand. Some of the areas related to this field are object detection or their classification but also areas like facial recognition or motion tracking.
- Robotics: the goal of this field is to create robots for different purposes and scenarios. Although the field is not strictly related to AI, given that not all the robots need to be "intelligent", many types of autonomous robots are developed within the AI community to solve problems in the real world that need an enhanced level of understanding such as search and rescue missions or self-driving delivery in dynamics environments. The AI focuses on the "brain" of the robot and one of the goals is certainly to create robots that are similar to us: able to interact with the environment and understand it.
- Machine Learning: in this field the methodologies are able to learn from data or experience instead of being programmed to solve specific tasks. The field is vast and general because the same methodology can be applied to different context as long as the data are similar. This has made the field grow exponentially and it is currently one of the main focuses of research and other fields such as Computer Vision or Natural Language Processing use Machine Learning (ML) methodologies. ML is further discussed in the section below.
Intro to Machine Learning
As mentioned in the previous section, one of the subfields of Artificial Intelligence is called Machine Learning and, as the name suggests, the main goal is to create methodologies and algorithms that allow the machines to learn. This is different from the typical way in which computer programs are created. Typically a program that needs to solve a specific problem is explicitly coded with all the steps required to solve that specific problem. On the other hand, in Machine Learning the methodologies learn from the data that they receive and try to use them for the specific task that they need to address instead of being specifically coded for it. There are three main subcategories of ML which are Supervised Learning, Unsupervised Learning and Reinforcement Learning and they have methodologies used to solve different types of problems.
Supervised Learning
In Supervised Learning the user needs to provide some input data but also the desired output associated to the input data. These are called "Labelled Data". In the Figure 3 example (click to zoom it) you can see in the background that the input data are the different solids with their associated names which is the output. Given enough data the computer is able to learn the main characteristics of a cube and the sphere so once it is presented with new data not seen before still manages to label them correctly. Essentially, the computer has learned the relationships between the input and the output. Two different problems that are solved with supervised learning techniques are Regression and Classification.

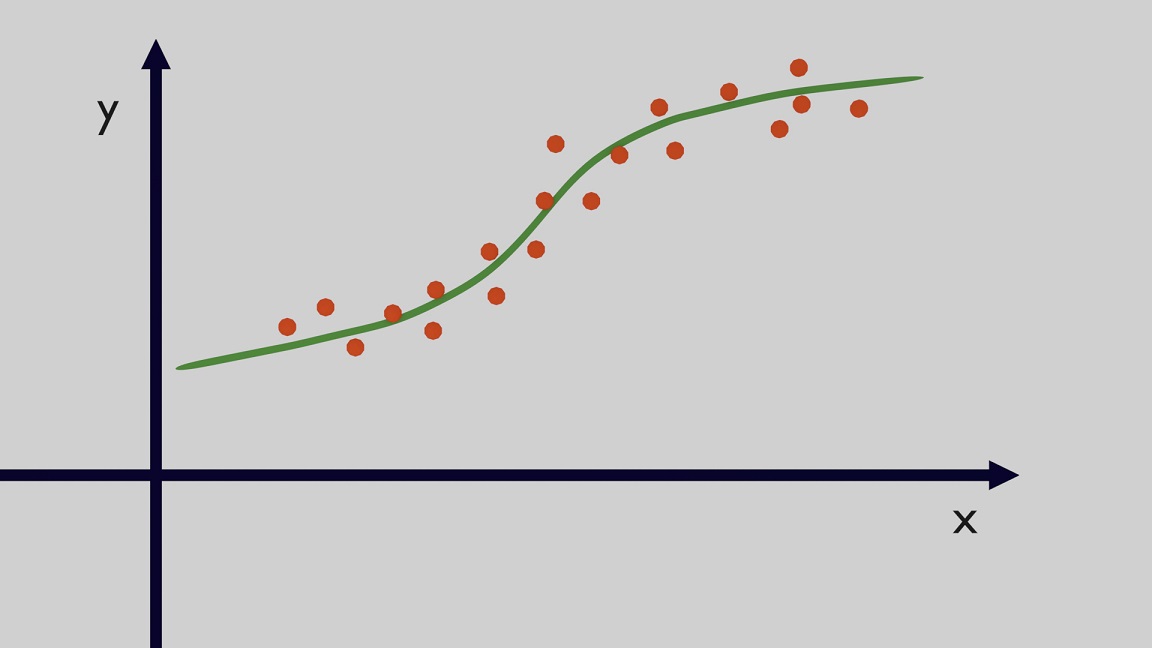
In the case of Regression, the main goal is to typically predict continuous quantities and to find the function that is better able to represent the input data. In the Figure 4 example you can see that the inputs are the orange points and the green function is a good fit for the data. Now it is clear that many types of functions can be created and one of the tasks is also to understand when to stop and what function be considered good enough to make predictions using unseen data.
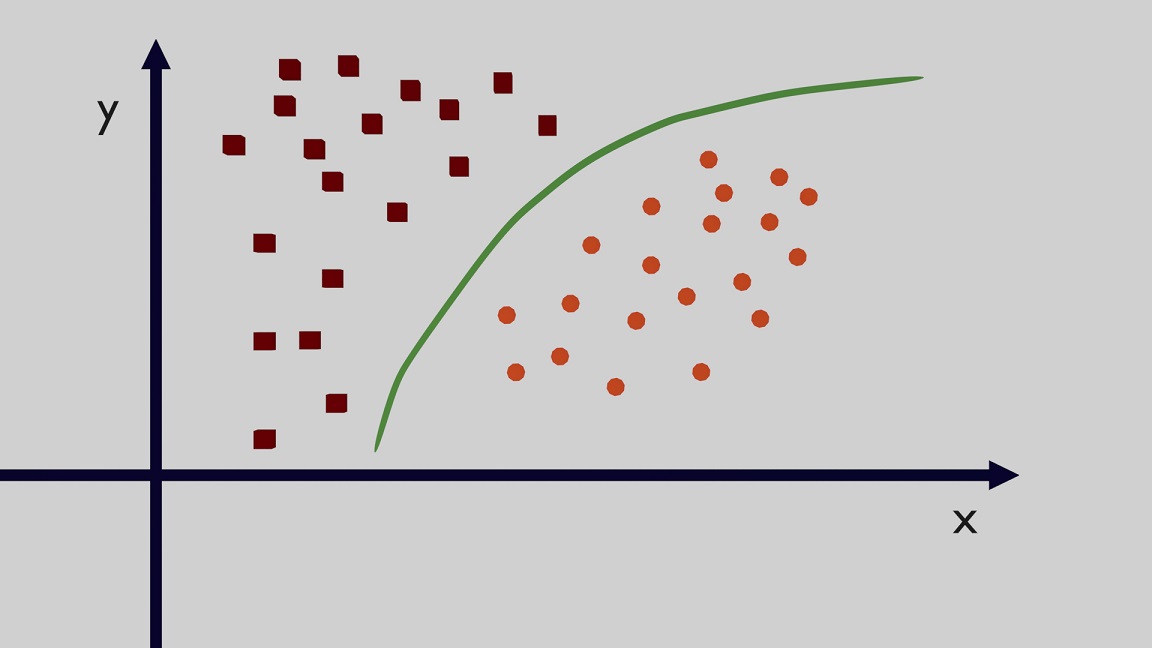
In a Classification problem shown in Figure 5, similarly to the one previously shown with the Cubes and the Spheres, there is a discrete number of classes and the main objective is to divide this classes with some bounds so that the method is able to associate an input to a specific class. In the example you can see that the bound divides the space into two parts and each part is associated to a specific class. It is worth mentioning that these methods are also used in case of more than 2 classes.
Unsupervised Learning
In Unsupervised Learning the data are unlabeled because the output is not known and only the input is provided. So essentially the user does not exactly know what to expect from the data but would like to use a method that is able to find some patterns or relationships within the data. In the example in Figure 6, you can see that in the background different solids are provided and then the computer is able to divided them into 3 different groups based on their shapes. Two problems that are solved with unsupervised learning methodologies are Clustering and Dimensionality Reduction.

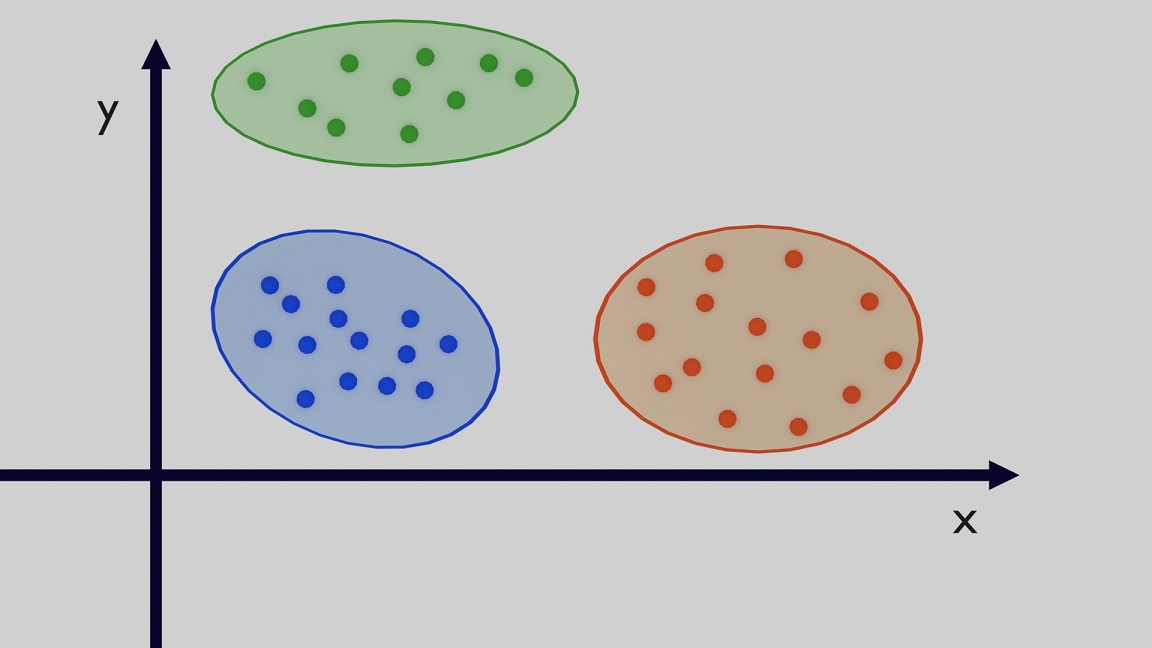
In a Clustering Problem, the main goal is to group input data which have similar properties. In the example in Figure 7 there are some data which share similar properties so they are close to each other and the algorithm groups them together. This problem is the same previously shown with the solids where the computer was able to find patterns in the data which then were used to split them into different groups.
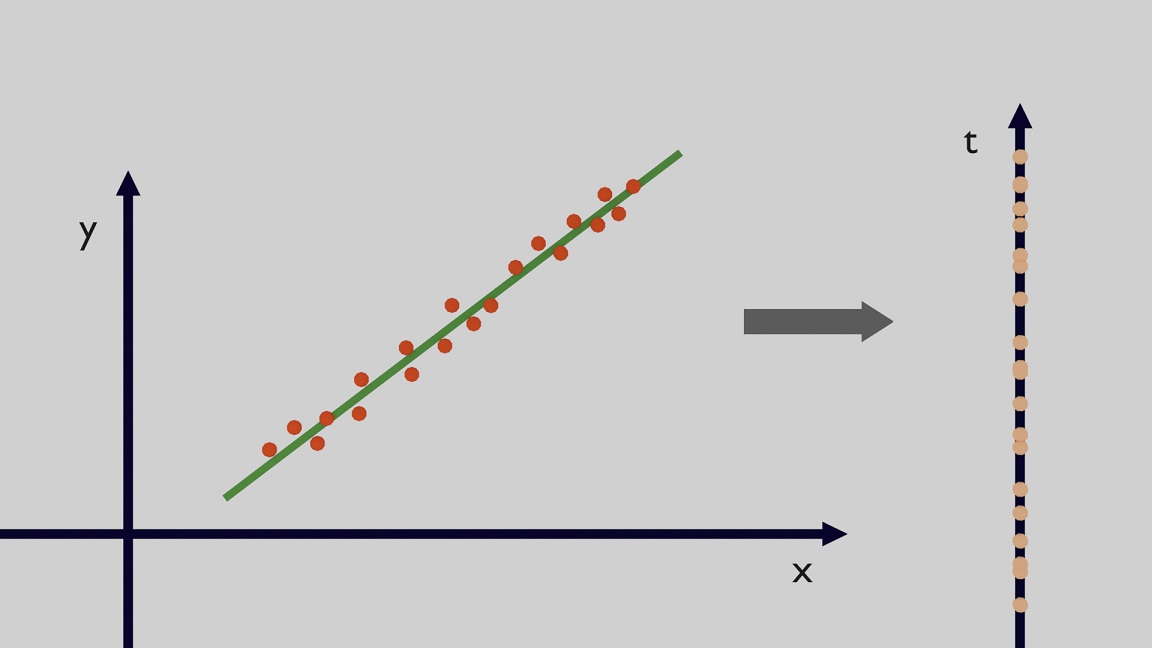
In a Dimensionality Reduction Problem, the objective is to reduce the initial dimension of the data. The idea is that some of the information is redundant or not particularly important and by removing this information it is still possible to keep the essence of the data. It is typically important to find a trade-off in order to avoid excessive loss of information but also have less dimensions which might help the convergence of the algorithms and also the overall training speed. In the example in Figure 8 the 2-dimensional data can be reduced into a single dimension because the 2 variables are strongly correlated.
Reinforcement Learning
In Reinforcement Learning (RL), this is quite different from the others two. Here it is introduced the concept of Agent which is essentially an entity (like a program) that makes decisions. By doing so it is interacting with an environment which is essentially a place where the Agent can make decisions and see the result from these decisions. The actions lead to rewards which can be positive or negative and the Agent needs to learn by keep trying making decisions and actions in the environment (Figure 9). This is a trial and error approach where the learning is based on the rewards provided by the environment.
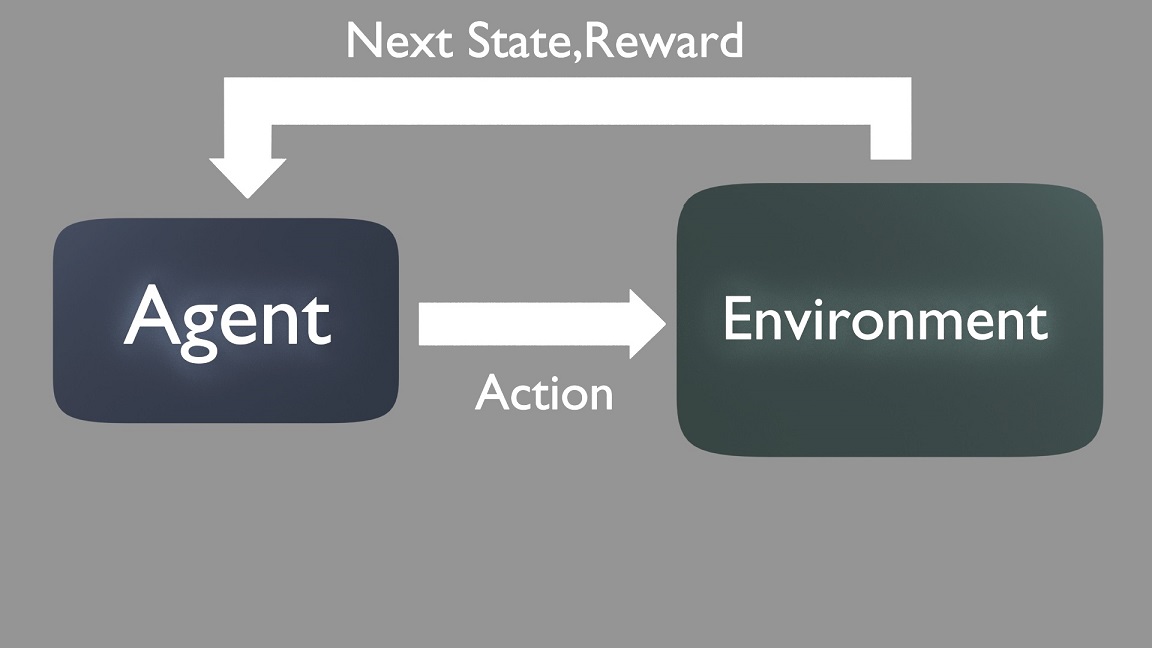
It seems quite theoretical but in practice, let's imagine a robot in a maze. The objective is to escape the maze and reach the green tile. The robot keeps trying to perform some actions in the environment which is the maze in this case. In some cases go left, other cases right and so on. If the robot hits the wall it receives a negative reward and if goes over the red tiles which are traps the rewards are very negative. This is repeated many times so that the robot can get feedback from all the actions made in the environment and after several attempts it will be able to reach the exit without touching any red tile or bumping into the walls of the maze.

The video about this introduction of Artificial Intelligence and Machine Learning, with all animated examples, can be found below.
Comment on Reddit
Related Pages
- [1] An example problem which uses Linear Regression: The Long Journey Problem
- [2] An example problem which uses Polynomial Regression: The Rescue Mission
- [3] Code of Linear Regression created from scratch in Python using only main equations
- [4] Code of Polynomial Regression created from scratch in Python using only main equations
- [5] Details and formulas of some common Regression Metrics: MAE, RMSE, MSE, R2
Latest AI and ML Pages
- [1] Python code of common Regression Metrics from scratch and also by using sklearn
- [2] Interactive Polynomial Regression Code modifiable by the user in Javascript
- [3] Polynomial Regression is used to predict Coronavirus cases with scikit-learn
- [4] An example problem which uses Polynomial Regression: The Rescue Mission
- [5] Code of Polynomial Regression created from scratch in Python using only main equations
Top AI and ML Pages
- [1] Introduction to Artificial Intelligence and Machine Learning
- [2] Details and formulas of some common Regression Metrics: MAE, RMSE, MSE, R2
- [3] Introduction to Linear Regression, main equations and concepts
- [4] Introduction to Polynomial Regression, main equations and concepts
- [5] Linear Regression is used to predict the house prices with scikit-learn